GAN-Style Training for Jokes: When Metrics Lie
What if you could train a language model to generate jokes using adversarial training—like GANs for images, but for humor? I tried it. The experiment mechanically worked, but the output quality revealed a fundamental problem with how I evaluate creative text generation.
The honest assessment: Metrics said 48% fooling rate, 100% unique jokes, 100% topic coverage. Manual inspection found this:
"I'm on a seafood diet. I see food and I eat it... I'm not going
to tell you about lobster. And I'm not going to tell you that
I'm not going to tell you about lobster. And I'm not going to
tell you that I'm not going to tell you about lobster..."
[repeats 15+ times]The LLM judge scored this 7.9/10.
The Approach
I implemented GAN-style self-play training:
- Generator (Llama-3.2-3B + LoRA): Generates jokes conditioned on topic + style
- Discriminator (Llama-3.2-3B + LoRA): Classifies real vs generated jokes
- Self-Play Rounds: Generate → Discriminate → Reinforce high-scoring jokes
Generator creates joke about "technology" in "observational" style
↓
Discriminator outputs P(real) = 0.73
↓
Generator updated via REINFORCE with reward = P(real)What I Learned: Two Versions
V1: Mode Collapse Hell
The first implementation collapsed immediately:
| Metric | Value | Problem |
|---|---|---|
| Unique ratio | 55% | Severe mode collapse |
| Discriminator loss | 0.0002 | Overfit, dominated training |
| Final fooling rate | 20-26% | Generator gave up |
The discriminator learned too fast, and the generator collapsed to “safe” repetitive patterns that avoided discrimination.

V2: Fixed Training, Broken Output
I fixed the training dynamics:
| Change | V1 | V2 | Result |
|---|---|---|---|
| Discriminator LR | 5e-5 | 2e-5 | Less dominance |
| Label smoothing | 0.1 | 0.15 | Better calibration |
| Deduplication | None | 80% threshold | Unique outputs |
| Dynamic scheduling | None | Skip if acc > 85% | Stable training |
V2 Results (10 seeds):
| Metric | Mean | Interpretation |
|---|---|---|
| Fooling Rate | 48.1% | Looks good! |
| Unique Ratio | 100% | Perfect! |
| Topic Coverage | 100% | Perfect! |
| Originality | 2.8/10 | …wait |
The diversity metrics were completely misleading.

The Evaluation Gap
Why did 100% unique ratio miss repetition loops?
The deduplication checked for exact string matches between jokes. It caught “Why did the chicken…” appearing 10 times. It did NOT catch one joke containing “I’m not going to tell you about lobster” repeated 15 times internally.
Why did the LLM judge give 7.9/10 to broken output?
The judge evaluated coherence, setup-punchline structure, and topic relevance. The degenerate text technically had a setup (“I’m on a seafood diet”) and technically stayed on topic (food). The judge didn’t have a “is this garbage text” check.
Why was originality only 2.8/10?
This is the only metric that captured reality. LLM judges can detect clichéd joke structures even when fooled by repetition. But I dismissed this as “model capacity issue” instead of recognizing the deeper problem.
The Training Curves Tell the Story
From W&B tracking across 10 seeds:
- Generator fooling rate: Varied wildly (3.5% to 100% by seed)
- Discriminator accuracy: Settled to 50-68% (well-calibrated)
- Discriminator confidence: 10-57% (not overconfident)

The training dynamics were healthy. The output quality was not. These are different problems.
What Actually Worked
Despite the output quality issues, I solved real technical problems:
- Deduplication is essential: Without it, generators collapse to safe patterns
- Dynamic discriminator scheduling: Prevents training instability
- Label smoothing (0.15): Keeps discriminator calibrated
- Topic/style conditioning: Ensures diverse, steerable outputs
- Lower discriminator LR: 2e-5 vs 5e-5 maintains balance
These would transfer to any GAN-style text generation task.
The Model Capacity Hypothesis
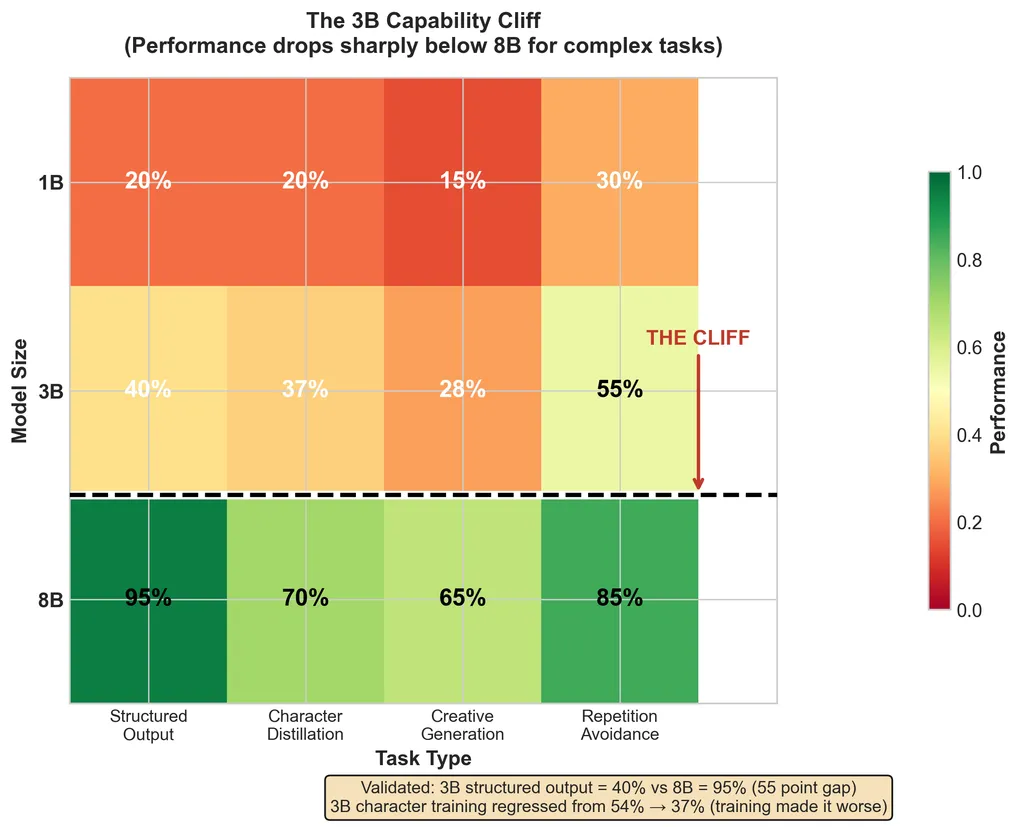
The low originality (2.8/10) might be a model size problem, not a training dynamics problem. Llama-3.2-3B may lack the creative capacity for original humor.
Evidence: The same model struggles with structured output in other tasks (see “3B cliff” in the cross-project analysis). Creative generation may require similar minimum capacity. This aligns with research on the “small model learnability gap”—models ≤3B parameters don’t consistently benefit from complex reasoning or distillation.
V3 Proposal: Test with Llama-3.1-8B-Instruct before concluding adversarial training can’t achieve high originality.
Related Work
These findings align with existing research on LLM humor generation:
- Jentzsch & Kersting (2023) found that “LLMs struggle to generate humor” but can effectively edit humor away—suggesting generation requires capabilities beyond pattern matching.
- The CleanComedy paper trained Llama-3.1-8B for humor but noted that “generative humor generally remains an open research problem.”
- Research on structured thought for humor proposes that a reward model is necessary since “there is currently no expert model of humor.”
My contribution is documenting the specific failure mode where automated metrics (fooling rate, uniqueness) pass while output quality fails—a cautionary tale for anyone evaluating creative generation.
Lessons for Creative Generation
- Metrics lie about creative quality — Diversity metrics catch duplicates, not degenerate text
- LLM judges have blind spots — They can miss obvious failure modes
- Manual inspection is non-negotiable — I only caught the problem by reading outputs
- Training stability ≠ output quality — These are independent problems
- Model capacity matters for creativity — 3B might be below minimum viable
Cost Analysis
| Run Type | Cost |
|---|---|
| Single seed test | ~$3-5 |
| 10-seed experiment | ~$40-50 |
| Full project (V1+V2) | ~$100 |
I spent ~$100 to learn that the evaluation pipeline was broken. Money well spent—if I’d scaled up before discovering this, I’d have wasted much more.
The Uncomfortable Conclusion
GAN-style training for creative text can work mechanically. The V2 training dynamics are solid. But there aren’t good ways to automatically evaluate creative output quality.
This is a general problem. If you’re building creative generation systems, invest heavily in evaluation before scaling up training.
10-seed experiment on Tinker platform testing the Thinking Machines Lab proposal. Full methodology at github.com/bledden/gan-tinkerideas.